So far we are missing 9,7 from the dataset, but today after class I'm going to add the rest.
 |
| FO logic symbols and digits 0-9 except 9,7 (25 total classes) |
Parsing
I've modified the basic python script I've been using for parsing to include stuff about subscripts.
This code will most likely be completely changed within the week, but this is simple prototyping to get a feel for the problem space.
I'm searching out tools and papers to help. I'm planning to try to finish parsing as fast as possible so that I can get back to perfecting the classification/extraction parts of the pipeline.
Right now I'm assuming that the extraction file will output position information similar to what is described in this paper[0]. The following three images are all from [0]. I'm thinking that in addition to direction information distance will also have to be taken into account, so that implicit newlines can be added.

This will be then used to create a graph like so:
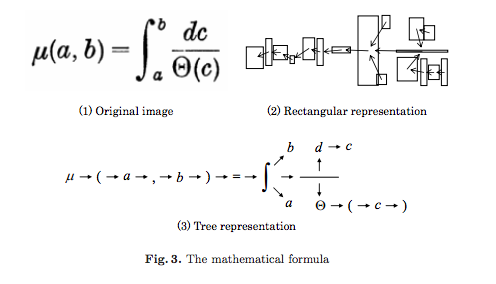
Then a graph representation will be used to determine if a symbol is a superscript/subscript/other and if the symbol should back-off its classification to another possible classification (e.g., negation shouldn't be a superscript, so if the second most probable symbol is a 2 it should output)

I used some of the holdout data to make symbols to represent 2^12. I hardcoded the positional information and edited the parser file to use this data.
 |
| Output of the play parser for superscripts |
Some papers I'm going to be looking at:
Tree Grammar
http://www.mkm-ig.org/meetings/mkm06/Presentations/Sexton.pdf
Towards a Parser for Mathematical Formula Recognition
Tools I'm looking into are:
No comments:
Post a Comment