We've completed adding digits to the dataset.
There is a disunity in our dataset where a few of the symbols were made binary. We're going to test to see if this helps classification by making all the data binary and re-training the classifier.
If accuracy improves, we'll make binary thresholding part of pre-processing. If it doesn't help, we'll revert the data and re-add the now binary images as non-binary.
_______________________________________________________________________________
I've begun work on the parser. As I haven't taken compilers yet , I've found it hard to begin but I've been exploring the problem space.
I've started to play with PLY, a python implementation of lex and yacc. Using this I've made a hacky thing that can substitute some of the characters.
The parser has three overlapping goals:
1) substituting the classifier's coded output with the corresponding LaTeX
0 -> \forall
2) Using the CFG and positional data to make the subscripts and superscripts work:
56 with positional data "6 is to the upper left of 5" -> x^{y}
3) When the parser encounters syntactic errors, the parser should "back-off" the soft classifier results (i.e., the top 3 classes the symbol could be) to a symbol that fits the CFG
I talked to professor Jhala and he gave me some advice:
I have to do 3 steps,
1) Create a parse tree based on the code/position info from the classifier.
2) Evaluate different possible trees by "backing-off" some of the classifications.
3) Read off the tree to translate it to LaTeX
He also pointed me to the following links:
An Ocaml parsing homework assignment for CSE130
Happy, a parser generator for Haskell
A blog post about using Happy to write a compiler that might be useful
Showing posts with label datasets. Show all posts
Showing posts with label datasets. Show all posts
Wednesday, May 30, 2012
Wednesday, May 23, 2012
Expanding to Digits, Beginning Parser Stuff
We are expanding our dataset to include digits, which will allow us to start fooling around with super/subscripts!



[0] Verification of Mathematical Formulae Based on a Combination of Context-Free Grammar and
Tree Grammar
http://www.mkm-ig.org/meetings/mkm06/Presentations/Sexton.pdf
So far we are missing 9,7 from the dataset, but today after class I'm going to add the rest.
 |
| FO logic symbols and digits 0-9 except 9,7 (25 total classes) |
Parsing
I've modified the basic python script I've been using for parsing to include stuff about subscripts.
This code will most likely be completely changed within the week, but this is simple prototyping to get a feel for the problem space.
I'm searching out tools and papers to help. I'm planning to try to finish parsing as fast as possible so that I can get back to perfecting the classification/extraction parts of the pipeline.
Right now I'm assuming that the extraction file will output position information similar to what is described in this paper[0]. The following three images are all from [0]. I'm thinking that in addition to direction information distance will also have to be taken into account, so that implicit newlines can be added.

This will be then used to create a graph like so:
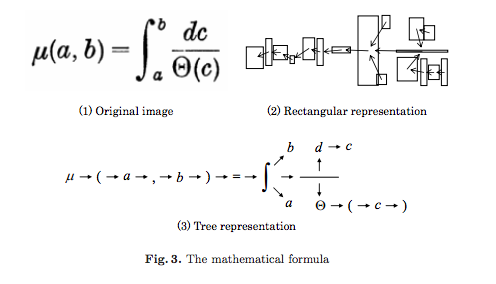
Then a graph representation will be used to determine if a symbol is a superscript/subscript/other and if the symbol should back-off its classification to another possible classification (e.g., negation shouldn't be a superscript, so if the second most probable symbol is a 2 it should output)

I used some of the holdout data to make symbols to represent 2^12. I hardcoded the positional information and edited the parser file to use this data.
 |
| Output of the play parser for superscripts |
Some papers I'm going to be looking at:
Tree Grammar
http://www.mkm-ig.org/meetings/mkm06/Presentations/Sexton.pdf
Towards a Parser for Mathematical Formula Recognition
Tools I'm looking into are:
Wednesday, April 18, 2012
Pipeline + random updates
To help with planning the project I created a diagram of the planned pipeline for HERC using http://www.diagram.ly/. The most updated pipeline image can be found in the repo here.

As shown, the pre-processing, localization, and classification components have "Basic Functionality" implemented, though they have a long way to go until they have "Decent Functionality".
A current goal is the try to get all the components "Basic Functionality" implemented (even if they don't exactly "work") so we can do ceiling analysis. Ceiling analysis is where you see how much a part of the pipeline working 100% would increase overall performance of the system. To do this you iteratively hand feed correct results from each part to the rest of the parts and see how much the entire systems accuracy increases.
This is a method to help prioritize which parts of the pipeline to work on. More information can be found on the Stanford ml-class preview videos site in unit XVIII video "Ceiling Analysis: What Part of the Pipeline to Work on Next "
________________________________________________________________________
Last post, we implemented cross validation and discovered that our classifier didn't perform better than chance. We were just using the raw pixels so this wasn't too surprising.
I found a file on the matlab fileexchange for HOG(Histogram of Oriented Gradients) features. Putting our toy dataset through it transformed a 1000x24963 matrix into a 1000x83 matrix.
This significantly increased the speed it takes to run from 8 minutes for one fold to 5 folds in 32 seconds.
The accuracy also went up, from 5.7 to 11.4! Which is *better* than chance. Confusion matrices have been generated for each fold and put in mistakes.mat in the repo, but we haven't interpreted them yet to figure out where to go from here.
The speed increase made it easier to explore the effect of different values of the lambda parameter for regularized logistic regression .
The values
[0 0.0900 0.1000 0.1100 0.1250 0.1500 0.2000 0.5000 0.7500 1.0000
10.0000 20.0000] were tested.
The corresponding mean cross-validation accuracies were:
[10.5000 11.2000 11.4000 10.6000 11.2000 10.6000 10.3000 9.9000 10.3000 10.7000 9.6000 9.7000]
In the end .1, the value that lambda had originally been set to, worked best.
Accuracies for different values of lambda at each fold can be found here.
___________________________________________________________________________
We still haven't gotten around to figuring out how use some of the infty dataset. We need to parse some comma-separated values in .txt files to do this. Some of the dataset, however, was given in raw images. I passed these through the localizer to see how it performed. It does well (which is to be expected, as these aren't noisy handwritten images), but still has the same problems with non-connected parts.
 ____________________________________________________________________________
____________________________________________________________________________
A few things accomplished since monday:
{kind=link}

As shown, the pre-processing, localization, and classification components have "Basic Functionality" implemented, though they have a long way to go until they have "Decent Functionality".
A current goal is the try to get all the components "Basic Functionality" implemented (even if they don't exactly "work") so we can do ceiling analysis. Ceiling analysis is where you see how much a part of the pipeline working 100% would increase overall performance of the system. To do this you iteratively hand feed correct results from each part to the rest of the parts and see how much the entire systems accuracy increases.
This is a method to help prioritize which parts of the pipeline to work on. More information can be found on the Stanford ml-class preview videos site in unit XVIII video "Ceiling Analysis: What Part of the Pipeline to Work on Next "
________________________________________________________________________
Classifier Improvement
Last post, we implemented cross validation and discovered that our classifier didn't perform better than chance. We were just using the raw pixels so this wasn't too surprising.
I found a file on the matlab fileexchange for HOG(Histogram of Oriented Gradients) features. Putting our toy dataset through it transformed a 1000x24963 matrix into a 1000x83 matrix.
This significantly increased the speed it takes to run from 8 minutes for one fold to 5 folds in 32 seconds.
The accuracy also went up, from 5.7 to 11.4! Which is *better* than chance. Confusion matrices have been generated for each fold and put in mistakes.mat in the repo, but we haven't interpreted them yet to figure out where to go from here.
The speed increase made it easier to explore the effect of different values of the lambda parameter for regularized logistic regression .
 |
| High values of lambda didn't help |
 |
| Exploring closer to .1 |
The values
[0 0.0900 0.1000 0.1100 0.1250 0.1500 0.2000 0.5000 0.7500 1.0000
10.0000 20.0000] were tested.
The corresponding mean cross-validation accuracies were:
[10.5000 11.2000 11.4000 10.6000 11.2000 10.6000 10.3000 9.9000 10.3000 10.7000 9.6000 9.7000]
In the end .1, the value that lambda had originally been set to, worked best.
Accuracies for different values of lambda at each fold can be found here.
___________________________________________________________________________
Localization Update
We still haven't gotten around to figuring out how use some of the infty dataset. We need to parse some comma-separated values in .txt files to do this. Some of the dataset, however, was given in raw images. I passed these through the localizer to see how it performed. It does well (which is to be expected, as these aren't noisy handwritten images), but still has the same problems with non-connected parts.

Misc
A few things accomplished since monday:
- Cleaned up some code (vectorizing stuff, replacing own implementation of a few things with matlab commands, added/deleted/fixed comments)
- Started research on making synthetic data to expand toy dataset
- Made folder of each toy dataset sample as an individual image, to help with feature extraction/testing
Sunday, April 8, 2012
Preprocessing/Dataset progress
First, this one with preprocessing / dataset stuff.
Next, classifier stuff.
Then, localization/bounding box stuff.
Finally, a brief TODO for the week and notes on version control.
This is for ease of reading/accessing posts by content in the future.
We have begun to play with our toy dataset!
The first task was removing the black grid lines so our samples wouldn’t have a bunch of extraneous noise. Oren wrote a script that did a fantastic job of erasing these lines:
Here is an example of an original dataset image:

The result of the preprocessing script:

We would like to thank Jeanne Wang for bringing the inftyMDB dataset to our attention. We have downloaded it, and are currently trying to figure out how to use it.
The inftyMDB dataset can be found here
In our proposal we planned to use mechanical turk to generate a dataset by the end of the first week,however I feel we need a few more iterations of toy datasets and to use the inftyMDB dataset before we generate a final dataset.
Current dataset goals include:
Figure out how to use inftyMDB
possibly make toydataset2
finalize planned range of math symbols for dataset
The inftyMDB dataset can be found here
In our proposal we planned to use mechanical turk to generate a dataset by the end of the first week,however I feel we need a few more iterations of toy datasets and to use the inftyMDB dataset before we generate a final dataset.
Current dataset goals include:
Figure out how to use inftyMDB
possibly make toydataset2
finalize planned range of math symbols for dataset
Subscribe to:
Posts (Atom)