We've completed adding digits to the dataset.
There is a disunity in our dataset where a few of the symbols were made binary. We're going to test to see if this helps classification by making all the data binary and re-training the classifier.
If accuracy improves, we'll make binary thresholding part of pre-processing. If it doesn't help, we'll revert the data and re-add the now binary images as non-binary.
_______________________________________________________________________________
I've begun work on the parser. As I haven't taken compilers yet , I've found it hard to begin but I've been exploring the problem space.
I've started to play with PLY, a python implementation of lex and yacc. Using this I've made a hacky thing that can substitute some of the characters.
The parser has three overlapping goals:
1) substituting the classifier's coded output with the corresponding LaTeX
0 -> \forall
2) Using the CFG and positional data to make the subscripts and superscripts work:
56 with positional data "6 is to the upper left of 5" -> x^{y}
3) When the parser encounters syntactic errors, the parser should "back-off" the soft classifier results (i.e., the top 3 classes the symbol could be) to a symbol that fits the CFG
I talked to professor Jhala and he gave me some advice:
I have to do 3 steps,
1) Create a parse tree based on the code/position info from the classifier.
2) Evaluate different possible trees by "backing-off" some of the classifications.
3) Read off the tree to translate it to LaTeX
He also pointed me to the following links:
An Ocaml parsing homework assignment for CSE130
Happy, a parser generator for Haskell
A blog post about using Happy to write a compiler that might be useful
Showing posts with label parsing. Show all posts
Showing posts with label parsing. Show all posts
Wednesday, May 30, 2012
Wednesday, May 23, 2012
Expanding to Digits, Beginning Parser Stuff
We are expanding our dataset to include digits, which will allow us to start fooling around with super/subscripts!



[0] Verification of Mathematical Formulae Based on a Combination of Context-Free Grammar and
Tree Grammar
http://www.mkm-ig.org/meetings/mkm06/Presentations/Sexton.pdf
So far we are missing 9,7 from the dataset, but today after class I'm going to add the rest.
 |
| FO logic symbols and digits 0-9 except 9,7 (25 total classes) |
Parsing
I've modified the basic python script I've been using for parsing to include stuff about subscripts.
This code will most likely be completely changed within the week, but this is simple prototyping to get a feel for the problem space.
I'm searching out tools and papers to help. I'm planning to try to finish parsing as fast as possible so that I can get back to perfecting the classification/extraction parts of the pipeline.
Right now I'm assuming that the extraction file will output position information similar to what is described in this paper[0]. The following three images are all from [0]. I'm thinking that in addition to direction information distance will also have to be taken into account, so that implicit newlines can be added.

This will be then used to create a graph like so:
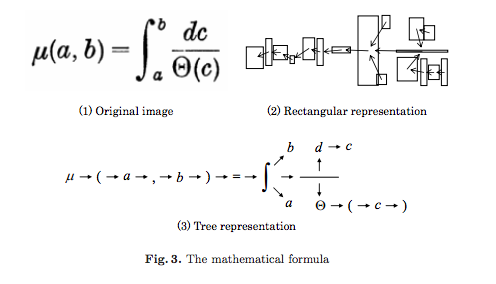
Then a graph representation will be used to determine if a symbol is a superscript/subscript/other and if the symbol should back-off its classification to another possible classification (e.g., negation shouldn't be a superscript, so if the second most probable symbol is a 2 it should output)

I used some of the holdout data to make symbols to represent 2^12. I hardcoded the positional information and edited the parser file to use this data.
 |
| Output of the play parser for superscripts |
Some papers I'm going to be looking at:
Tree Grammar
http://www.mkm-ig.org/meetings/mkm06/Presentations/Sexton.pdf
Towards a Parser for Mathematical Formula Recognition
Tools I'm looking into are:
Monday, April 23, 2012
Prototype: Iteration 1
All major parts of the pipeline have been touched now, and given basic functionality.

For ease of implementation, we decided that working with a proper subset of 1st order logic would be a reasonable goal. This allows us to get a "working" prototype while side-stepping issues like superscripts/subscripts and bounding box problems. As we get this prototype to increase accuracy on first-order logic, we will look into ways to expanding it to deal with more complex mathematical structures.
The subset of first-order logic that we will be working with for now includes the following symbols:
 |
| 16 symbols total |
It is quite literally a *proper* subset, as it only includes the proper subset symbol! In this scheme equals is created using not and not-equals.
New Dataset:
To help with this goal we have started creating a second toy dataset, made out of 300 examples each of 16 symbols. The scripts that do preprocessing and turn these images into matrices has been turned into functions that automate a lot of what we were doing tediously by matlab commands before.
So far we have 5 symbols finished.
Extraction:
Oren wrote code that takes the bounding boxes from the segmenter and extracts the characters into individual images. We are trying to keep this code as independent of the segmenter as possible. The extractor works well, but it is given lots of garbage by the segmenter.
The next iteration of this code will have to output positional information about the symbols as well, so that a graph structure can be created to help the parser.
Classification:
We have trained on the 5 symbols we have data for (forAll, exist, x, y, R,). Accuracy was greater than chance! However, only 2 classes were ever predicted (exist and x) so the 40% didn't seem very meaningful.
The next step with the classifier is the find new features, and to modify it so that it gives "soft" predictions of the top few most probable classes. This soft output will be helpful for the parser.
Parsing:
I wrote a simple substitution based linear parser in python using scipy/numpy. This was a task that was much easier doing in python than matlab. Creating complex graph structures and parsing them is not something I am looking forward to doing in matlab, but would be a joy in python, so I'm planning on using python for this process for the time being.
If we have time, the code may be ported to matlab (or the rest of the matlab code might be ported to python!!)!
Prototype Iteration 1 Demo:
To test the prototype the following formula was scanned:
 |
| This sentence is the definition of a function. |
We ran it through the segmenter, which output 21 boxes given these 7 symbols.
Of those, 6 were garbage from a smear on the paper. The rest were slight translations of the correct character extraction.
We cheated and filtered out the garbage and repetitions for the sake of a first demo. The seven selected images were then run through the classifier. The classifiers output was then run through the parser, resulting in the following .tex file:
 |
| LaTeX generated by parser. |
Which results in this after pdflatex:
 |
| Our systems prediction |
While the original samples true results should have been:
 |
| The correct classification/parsing |
TODO:
- Classification the most important now, we need to find features with greater discriminative power
- We have decided to read at least one computer vision paper a week in order to get ideas and get a good feel for what we should make our final paper look like.
- We need to start work on outputting the graph structure for the parser.
Looking ahead (perhaps too far), the following is a tentative list of how we will expand the scope of this project as the 1st order logic accuracy increases:
1) add numbers
2) add subscripts/superscripts
3) Discrete Math symbols
4) Calculus symbols
5) Linear Algebra (matrices)
6) ???????
7) Profit!!
I expect to get to at least 3, possibly 4. Once work begins on creating the graph structure for parsing, we can see how distant a goal linear algebra is.
Subscribe to:
Posts (Atom)